5-Day AI Agents Intensive Course with Google
The 5-Day AI Agents Intensive [November 10 2025- November 14 2025] is Google’s flagship hands-on program that turns developers into full-stack agentic engineers. Co-created by Google Research and Kaggle, it takes learners from prompting to production, covering models, tools, orchestration, memory, observability, and deployment. Each day blends theory and practice through Gemini-powered codelabs, expert whitepapers, and live sessions with Google engineers. By the end, participants don’t just understand agents — they build and deploy them.
🧪 Assignments
Each day paired NotebookLM podcasts and expert whitepapers with Kaggle codelabs where participants experimented with Gemini API, Embeddings, Vertex AI, and open-source frameworks like LangGraph. The week culminated in a Capstone Project — a full agent pipeline integrating tools, memory, and evaluation.
You can find the assignment & code in my GitHub repo
📅 5-Day Course Overview
Day 1: Introduction to Agents
Explore the foundational concepts of AI agents, their defining characteristics, and how agentic architectures differ from traditional LLM applications—laying the groundwork for building intelligent, autonomous systems.
Today marked the kickoff of my 5-day deep dive into the world of AI Agents — and let’s just say, it was mind-expanding. We’re no longer talking about prompt-response LLMs that simply autocomplete text. This new paradigm is about autonomous, goal-oriented systems that can reason, plan, act, and learn in continuous feedback loops. The shift from predictive AI to agentic AI feels like moving from single-threaded functions to a distributed intelligence system. These agents aren’t static models — they’re self-directed applications that integrate cognition (via LLMs), execution (via API tools), and governance (through orchestration layers).
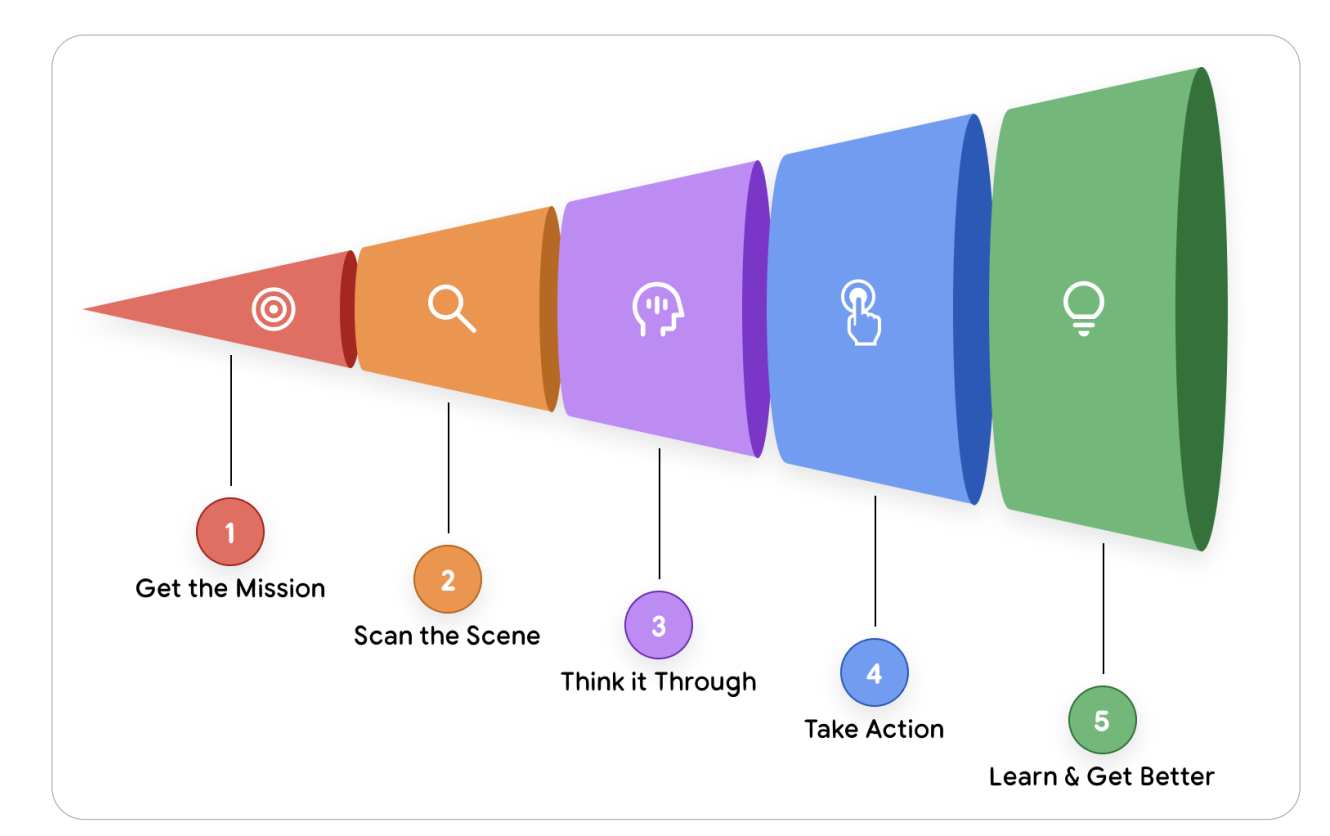 Figure 1 — The Agentic AI Problem-Solving Loop
Figure 1 — The Agentic AI Problem-Solving Loop
⚙️ Dissecting the Agent Stack — Brain, Hands, and Nervous System
- The Model (Brain): a foundation LLM like Gemini 2.5 Pro or GPT-4o that handles reasoning, logic, and semantic planning.
- Tools (Hands): APIs, databases, or code sandboxes that let the agent manipulate real-world data.
- Orchestration Layer (Nervous System): manages the “Think → Act → Observe” loop, applies ReAct and Chain-of-Thought techniques, dynamically curates context windows, and injects runtime memory.
We also explored context engineering — the next evolution of prompt engineering — where developers fine-tune what the model “pays attention to” by assembling system prompts, user intent, RAG-based memory, and API outputs into one cohesive thought stream.
🧩 Levels of Intelligence — From Single Brain to Multi-Agent Ecosystems
The session introduced a fascinating five-level taxonomy of agentic systems:
- Level 0 — Plain LLMs: isolated reasoning without real-world awareness.
- Level 1 — Connected Problem Solvers: agents using APIs and RAG for grounding.
- Level 2 — Strategic Planners: multi-step reasoners managing context and state.
- Level 3 — Collaborative Multi-Agent Systems: a “team of specialists” communicating via A2A protocols.
- Level 4 — Self-Evolving Systems: agents capable of autonomous tool creation and meta-reasoning.
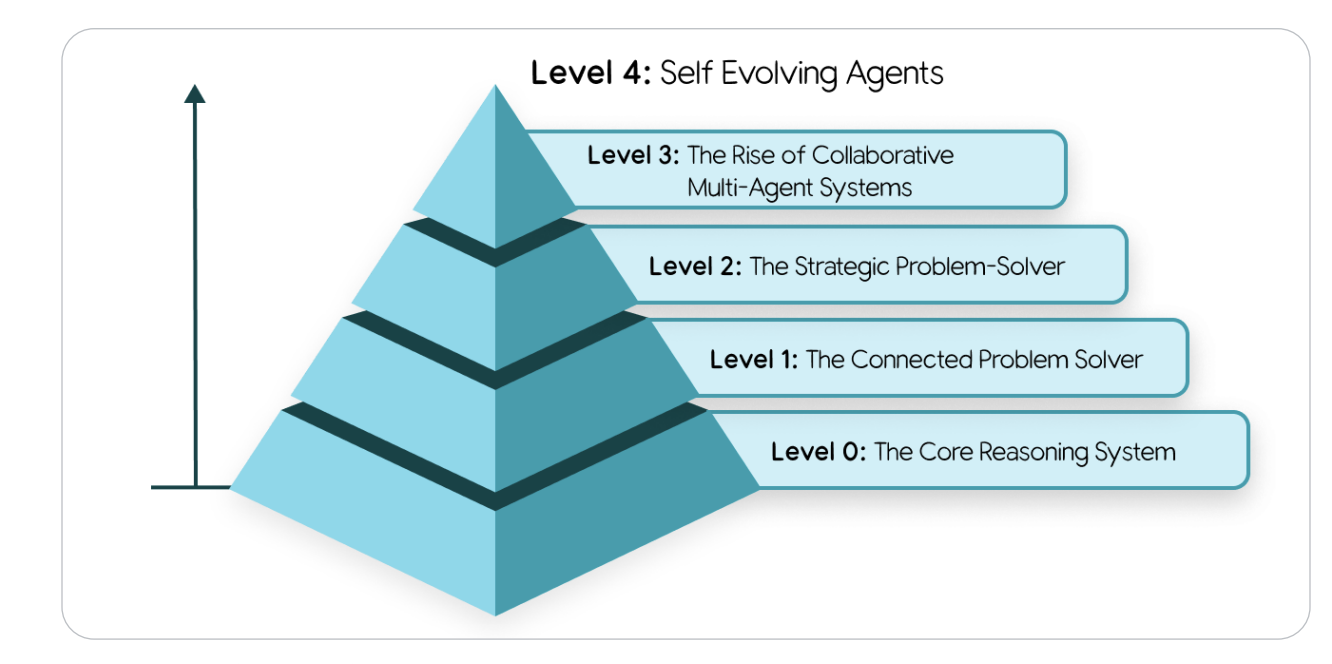 Figure 2 — Five Levels of Agentic Intelligence
Figure 2 — Five Levels of Agentic Intelligence
Examples like Google Co-Scientist (a research agent ecosystem that auto-generates and tests hypotheses) and AlphaEvolve (an evolutionary AI that iteratively evolves code) showed that this isn’t sci-fi anymore — it’s production-grade autonomy.
🧩 Multi-Agent Systems and Design Patterns
As problems scale in complexity, the idea of building a single, all-knowing “super-agent” quickly becomes impractical. Instead, the modern approach mirrors human organizations — a team of specialist agents, each mastering a focused domain. This modular architecture forms the backbone of a multi-agent system, where a large goal is decomposed into smaller, discrete subtasks executed by specialized AI agents. This design isn’t just elegant — it’s scalable, debuggable, and easier to evolve over time.
In this ecosystem, developers rely on agentic design patterns, much like system architects use distributed computing patterns. For dynamic, branching workflows, the Coordinator pattern acts like a project manager, decomposing complex goals, routing subtasks to expert agents (a researcher, a writer, a coder), and synthesizing the results. For more structured pipelines, the Sequential pattern works like a digital assembly line — the output of one agent becomes the input of the next. When quality assurance is critical, the Iterative Refinement pattern pairs a “generator” agent with a “critic” agent to form a self-improving feedback loop. And in safety-sensitive applications, the Human-in-the-Loop (HITL) pattern ensures that a person remains in control — introducing deliberate checkpoints before an agent executes high-impact decisions.
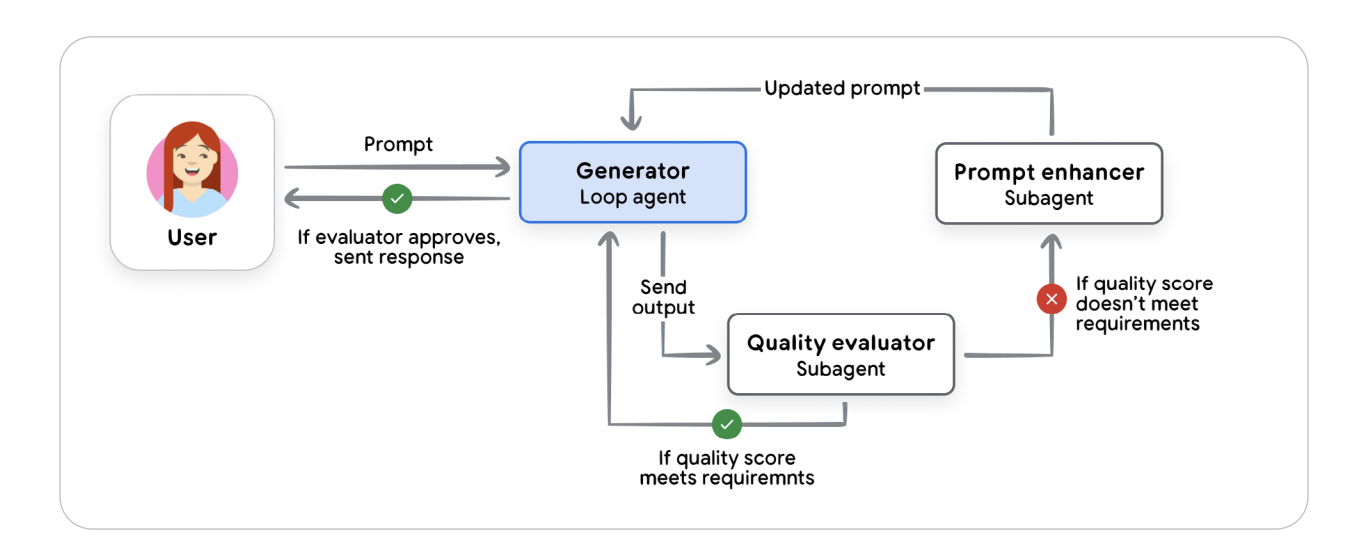 Figure 3 — Common Multi-Agent Design Patterns: Coordinator, Sequential, Iterative Refinement, and HITL
Figure 3 — Common Multi-Agent Design Patterns: Coordinator, Sequential, Iterative Refinement, and HITL
Together, these blueprints define the emerging agent engineering discipline — blending cognitive autonomy with classical software design thinking. They represent how agents can be structured, governed, and interconnected to operate like intelligent, collaborative microservices.
🧰 Developer Mindset 2.0 — AgentOps Is the New DevOps
As a backend engineer, what hooked me was AgentOps — the operational discipline for managing non-deterministic systems. Traditional unit tests don’t cut it when responses are stochastic. Instead, we use LM-as-Judge evaluations, OpenTelemetry traces, and metrics-driven development to validate reasoning quality, cost efficiency, and latency profiles. Deployment happens via Vertex AI Agent Engine or containerized stacks like Cloud Run and GKE.
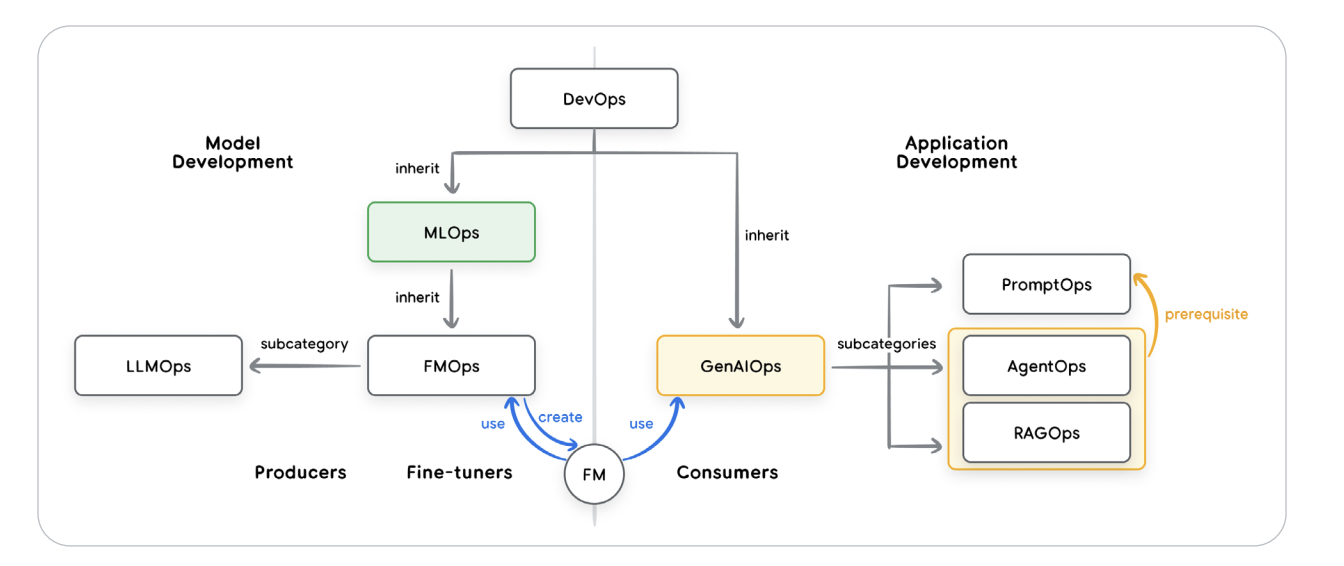 Figure 4 — Relationships between the operational domains of DevOps, MLOps, and GenAIOps
Figure 4 — Relationships between the operational domains of DevOps, MLOps, and GenAIOps
The best part? We’re now architecting intelligence, not just writing logic. Agent design feels like orchestrating microservices with cognition — each component has observability, identity, memory, and even a persona.
💡 Day 1 Takeaway and Assignment
Day 1 didn’t just teach me about agents — it reframed how I think about software itself. Developers are becoming system directors, managing fleets of autonomous reasoning entities. Our hands-on assignment was to build a simple agent loop using a language model, a mock API tool, and a basic orchestration layer to make the agent “think–act–observe” autonomously. I wired an LLM call with a pseudo-RAG component and live debug logging — essentially bootstrapping my first mini AgentOps pipeline.
You can find the assignment & whitepaper I used in my Github repo
Day 2: Agent Tools & Interoperability with MCP
Dive into the world of agent tools—understanding how AI agents can “take action” by leveraging external functionalities and APIs. Explore the Model Context Protocol (MCP) to discover and seamlessly use external tools and services with plug-and-play interoperability.
Day 2 was pure developer candy 🍬. After Day 1’s cognitive deep-dive, we dropped straight into the plumbing — the tooling stack that gives AI agents real-world powers. This session was the perfect mash-up of systems design, distributed computing, and protocol engineering — with enough JSON-RPC wizardry to make any backend nerd grin. The theme was clear: tools make agents useful. A model that can’t call an API is like a brain without hands.
🧠 Tools 101 — The Model’s Hands and the World’s API
We started with the basics: a tool is a callable function or program that extends an LLM’s capabilities — its “hands.” Two major types exist — knowledge tools (for retrieving data) and action tools (for executing tasks). The Weather Agent diagram showed get_weather() and convert_temperature_units() wired through MCP’s function-calling interface — a clean cascade of JSON-RPC requests and responses.
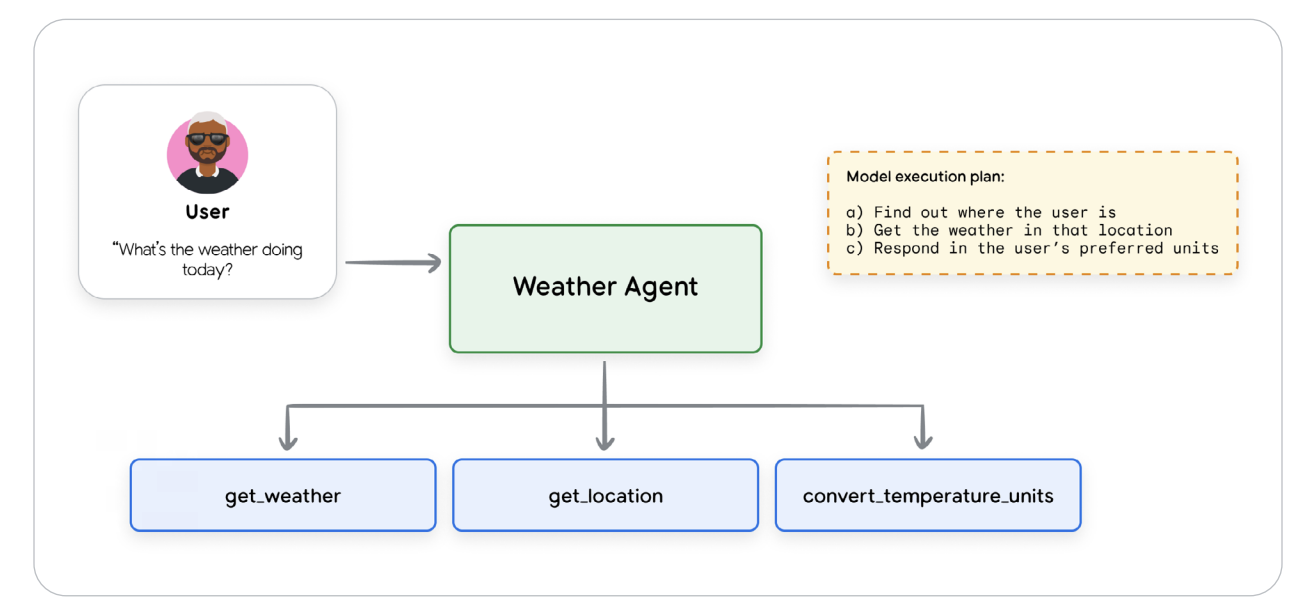 Figure 1 — Weather Agent Tool Call example
Figure 1 — Weather Agent Tool Call example
We explored three tool categories: Function Tools, Built-in Tools, and Agent Tools. Function Tools are simple Python functions wrapped in schemas. Built-in Tools are native to the model — Gemini includes Google Search, Code Execution, and Computer Use. Agent Tools are meta — one agent exposes itself as a tool to another, enabling Agent-to-Agent (A2A) composition. It’s literally “AI as a function.”
🔌 From Chaos to Protocol — Enter the Model Context Protocol (MCP)
Without a standard interface, connecting LLMs to tools is an N×M nightmare. Model Context Protocol (MCP) fixes this by acting as a universal contract for AI-to-tool communication — a kind of HTTP for Agents. It defines a clean three-tier architecture:
- Host — manages agent sessions and policy enforcement.
- Client — bridges LLM calls to MCP servers.
- Server — provides tools and capabilities (APIs, databases, services).
Each call flows as a JSON-RPC session (tools/call requests/responses) — green hosts, blue servers, connected by structured RPC pipes.
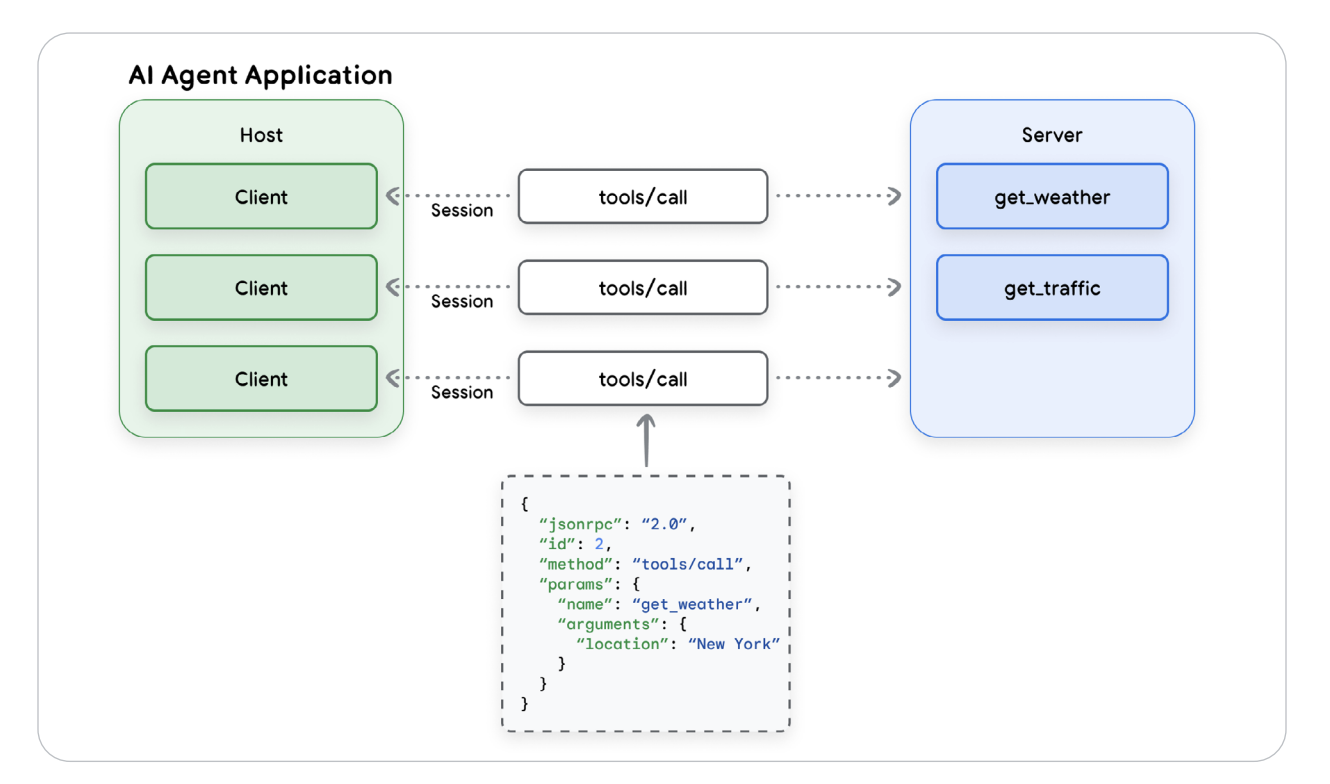 Figure 2 — MCP Host–Client–Server Architecture
Figure 2 — MCP Host–Client–Server Architecture
🧩 Primitives and Schemas — The Data Contracts of AI
The MCP spec defines six primitives: Tools, Resources, Prompts, Sampling, Elicitation, and Roots. Tools dominate — each defined by a JSON schema with inputSchema, outputSchema, and annotations like readOnlyHint and idempotentHint. It’s like OpenAPI for AI Ops — finally some type safety for LLMs.
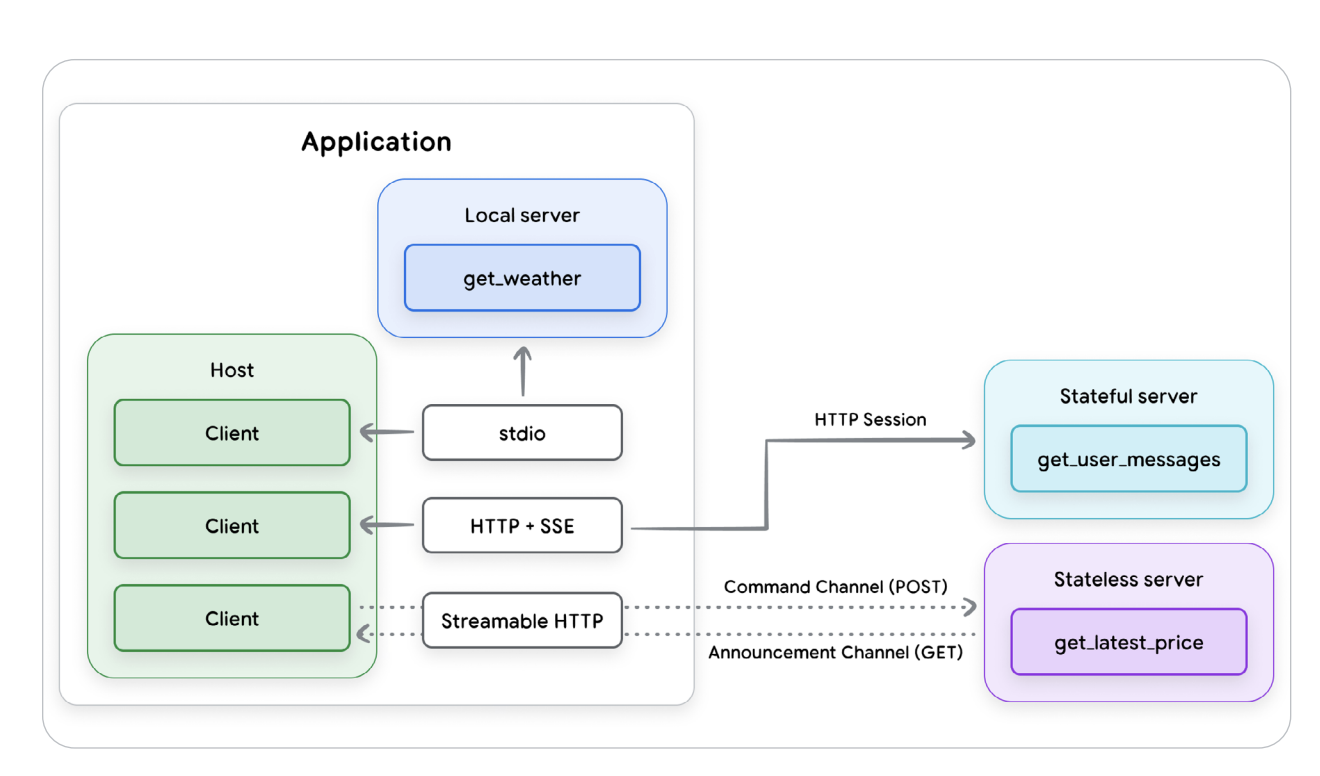 Figure 3 — MCP Transport Protocols
Figure 3 — MCP Transport Protocols
⚙️ Governance, Scalability & Security — The Enterprise Layer
MCP is powerful but risky: dynamic capability injection, tool shadowing, and the confused-deputy problem. We learned defensive patterns — explicit allowlists, mutual TLS, taint tracking, and Apigee gateways for policy enforcement.
🔬 Assignment — Building Our Own MCP Tool
Our assignment was hands-on: we built a mini MCP server exposing a custom tool (get_stock_price) with JSON schema validation. We wired a Gemini 2.5 Flash LLM client to discover and invoke it at runtime, tested mock data over Streamable HTTP, and validated outputs. In short, we built a mini API gateway that thinks for itself — and it worked like a charm.


💡 Day 2 Takeaway
If Day 1 was about teaching AI to think, Day 2 was about teaching it to act safely and at scale. The Model Context Protocol felt like the missing bridge between APIs and intelligence — a proper contract for AI autonomy. It was nerdy, elegant, and beautifully engineered.
You can find the assignment & code in my GitHub repo
Day 3: Context Engineering — Sessions & Memory
Learn how to build agents that remember and maintain context across interactions. Implement short-term sessions and long-term memory to create adaptive, context-aware systems capable of handling complex, multi-turn conversations.
If Day 1 gave agents a brain and Day 2 gave them hands, Day 3 gave them memory — the power to remember, forget, and evolve. This session felt like digital neuroscience: how large language models transition from stateless text predictors to stateful, context-aware entities. The core idea was Context Engineering — dynamically assembling the perfect mix of conversation history, system prompts, user memories, and retrieved data so that the agent always “knows” what matters right now.
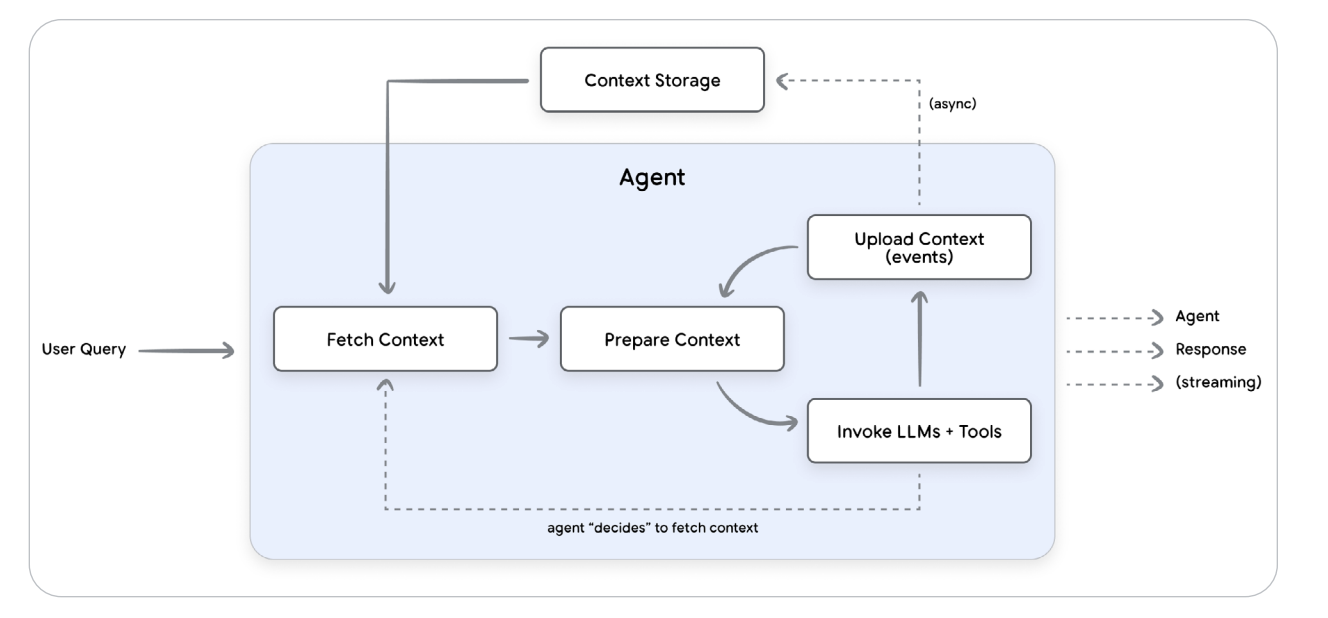 Figure 1 — Flow of Context Management for Agents
Figure 1 — Flow of Context Management for Agents
🧩 Context Engineering — From Prompting to State Management
LLMs are inherently stateless. Out of the box they forget everything between calls. Context Engineering fixes that by orchestrating sessions, memory managers, and retrieval pipelines to curate what sits inside the model’s context window at every step. Think of it as replacing static prompts with a dynamic orchestration layer that selects relevant instructions, examples, user memories, and RAG results in real time. Prompt engineering is the recipe; context engineering is the mise en place — the prep work that makes intelligent reasoning possible.
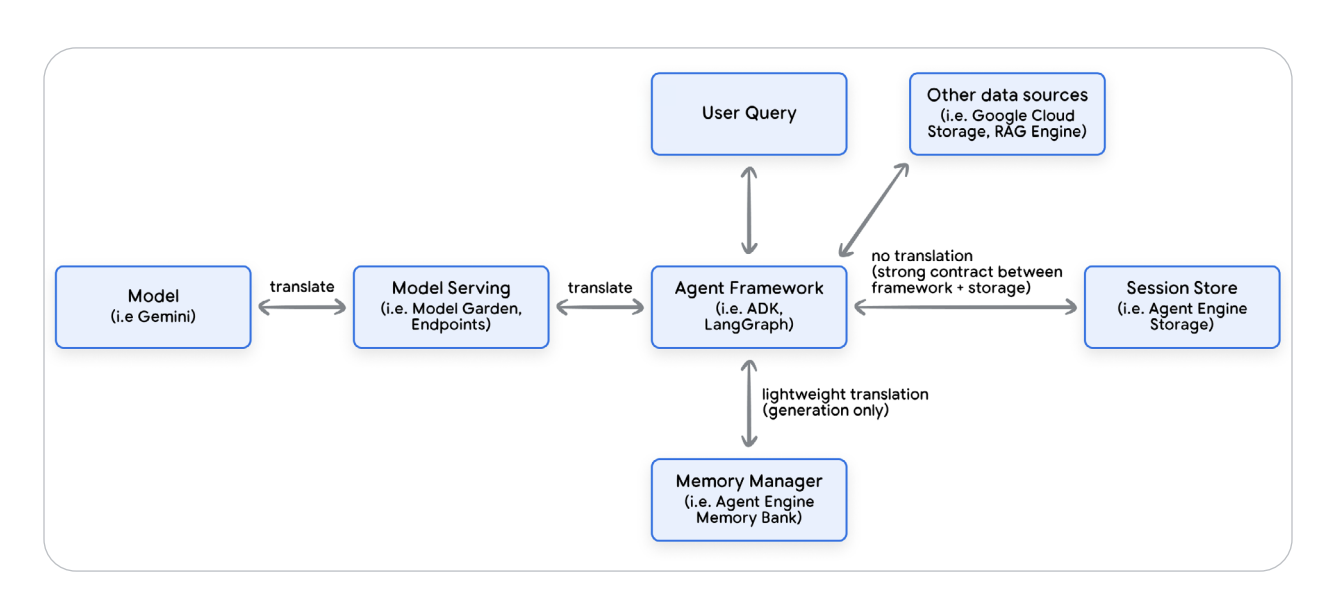 Figure 2 — Context Fetch → Prepare → Invoke → Upload Cycle
Figure 2 — Context Fetch → Prepare → Invoke → Upload Cycle
🤝 Multi-Agent Architectures — From Solo Reasoners to Collaborative Systems
One of the most fascinating visuals from Day 3 was the Multi-Agent Architecture Spectrum. It breaks down how agents evolve from working solo to collaborating in complex networks. A Single Agent setup is the simplest — one LLM paired with its tools, handling reasoning end-to-end. In a Network pattern, multiple agents communicate symmetrically, sharing knowledge to solve problems collectively. The Supervisor model introduces hierarchy — a central coordinator delegates tasks to sub-agents for parallel reasoning. The Supervisor-as-Tools design flips that hierarchy, where one agent invokes others as callable APIs. Hierarchical systems scale this idea further — layered supervisors manage specialized agent clusters, each responsible for sub-domains. Finally, Custom Architectures combine multiple paradigms into flexible, graph-like ecosystems optimized for real-world, interdependent tasks. Together, these designs mark the shift from isolated cognition to a fully collaborative, context-aware agent ecosystem capable of self-organization and adaptive problem-solving.
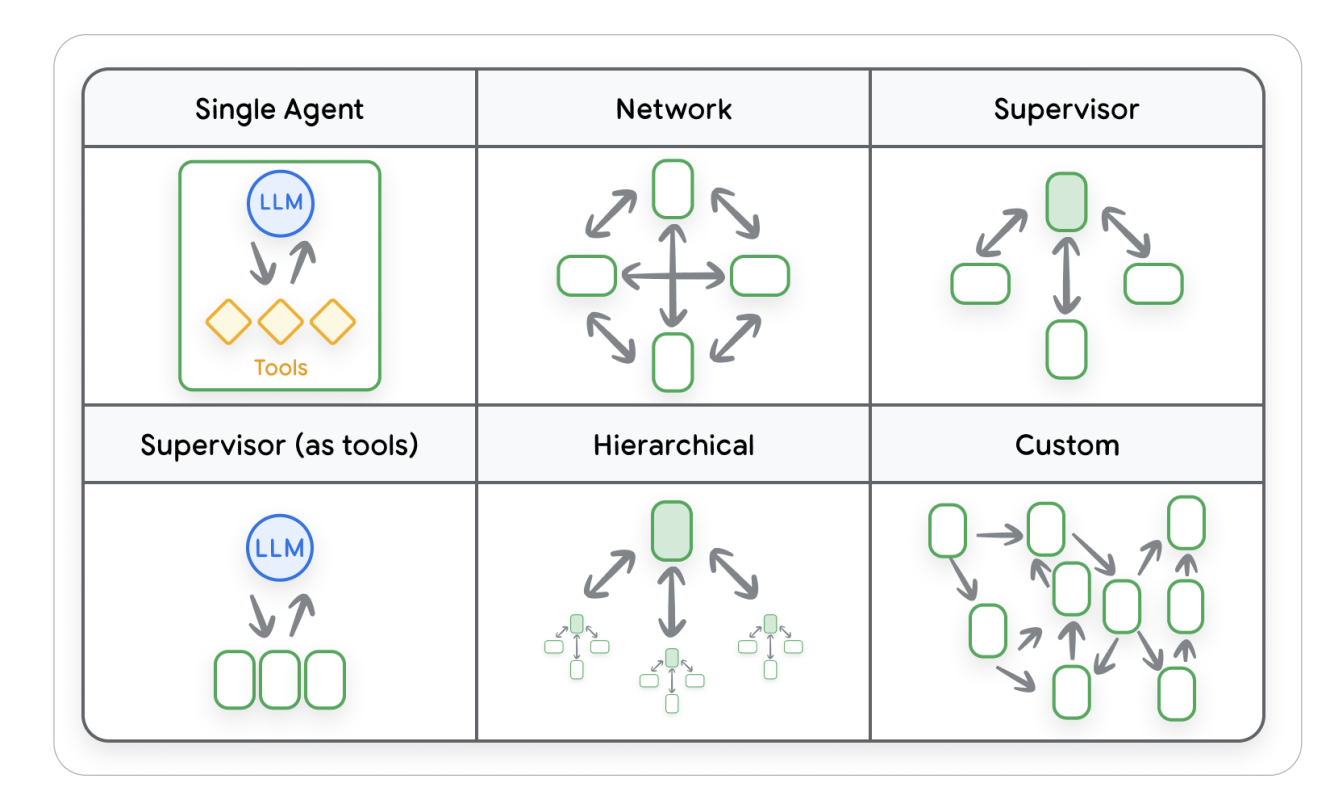 Figure 3 — Multi-Agent System Architectures: From Single Agent to Fully Networked Ecosystems
Figure 3 — Multi-Agent System Architectures: From Single Agent to Fully Networked Ecosystems
⚙️ Sessions — The Short-Term Memory of the AI Mind
A Session is the agent’s working desk — a mutable space that holds conversation events (user queries, model replies, tool calls) and state data. Frameworks implement this differently:
- ADK — explicit
SessionandEventobjects (log-based, append-only). - LangGraph — treats the entire state as a compacted session object.
- Multi-Agent Systems — share session logs via A2A protocols without losing isolation.
💾 Memory — Turning Conversations into Long-Term Knowledge
Then came Memory — the long-term knowledge layer that transforms raw chats into structured facts. It’s not “save history” — it’s an LLM-powered ETL pipeline that extracts key information, resolves conflicts, deduplicates entities, and stores them in vector databases or knowledge graphs for semantic retrieval. The memory loop is essentially self-curation for AI knowledge.
 Figure 4 — Memory Generation and Consolidation Pipeline
Figure 4 — Memory Generation and Consolidation Pipeline
🧠 Declarative vs Procedural Memory — Facts and Workflows
Memories split into two types: Declarative (facts and preferences) and Procedural (workflows and skills). Declarative memory lets agents know you; procedural memory lets them help you efficiently. Together, they mirror the human hippocampus and prefrontal cortex — data plus process. Stored across vector DBs and knowledge graphs, they enable hybrid semantic-graph reasoning.
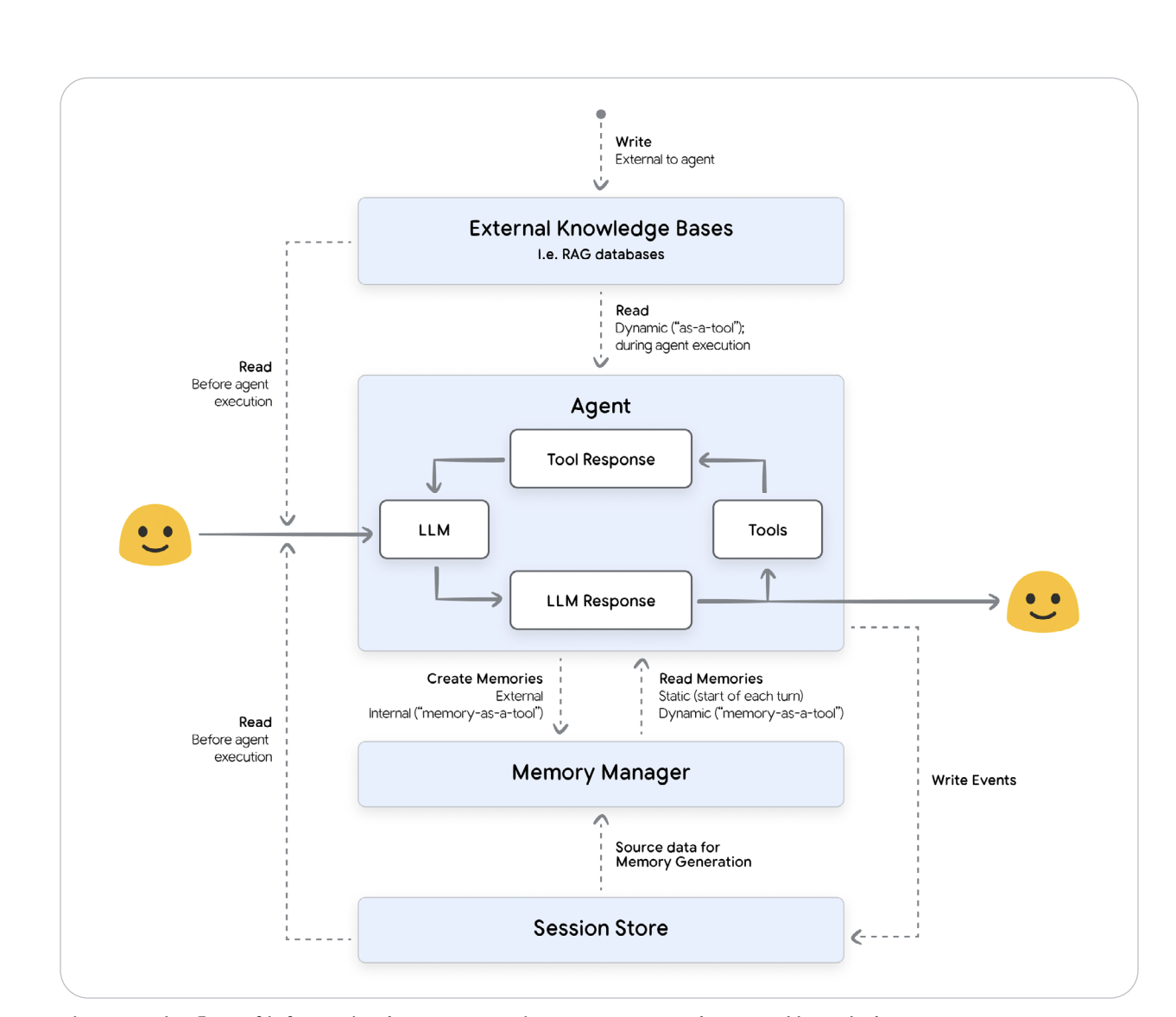 Figure 5 — Memory Provenance and Lineage
Figure 5 — Memory Provenance and Lineage
🔬 Assignment — Building a Memory-Enabled Agent
For the assignment, we implemented a Memory-as-a-Tool pattern using Google’s ADK. We built a custom tool generate_memories() to extract facts from chat sessions and persist them in the Agent Engine Memory Bank. The memory manager handled deduplication and provenance tracking before storing them in a vector database. Retrieval hooks then let the agent pre-load context or fetch relevant memories mid-conversation. Watching an agent recall something from two sessions ago felt like seeing synthetic cognition come alive.
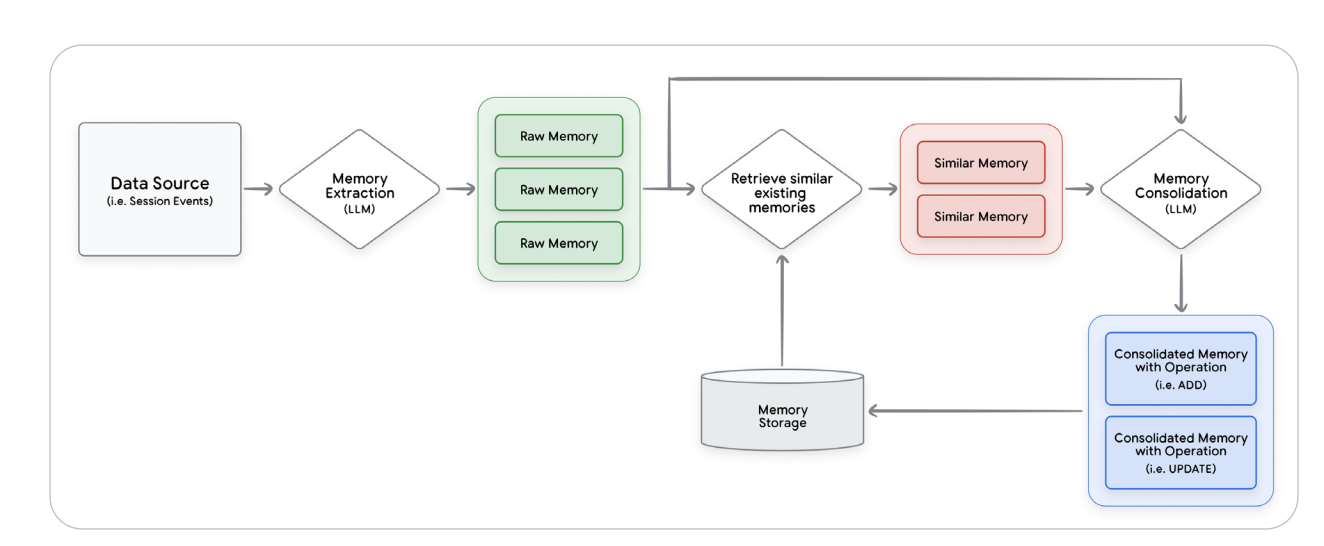 Figure 6 — ADK Memory Tool Implementation
Figure 6 — ADK Memory Tool Implementation
💡 Day 3 Takeaway
If Day 1 was about teaching AI to think and Day 2 was about teaching it to act, Day 3 was about teaching it to remember. Context Engineering isn’t prompt tuning — it’s AI systems design. Sessions provide short-term workspace; memory adds history and continuity. Together, they form the cognitive backbone of agentic AI. We’re no longer just coding logic; we’re building digital minds with memory hierarchies and self-curation pipelines.
You can find the assignment & code in my GitHub repo
Day 4: Agent Quality
Master the art of building reliable and high-quality agents through evaluation and observability. Gain hands-on experience with logging, tracing, and metrics to monitor your agents’ behavior and optimize their performance using LLM-as-a-Judge frameworks and quality benchmarks.
If Day 3 was about giving agents memory, Day 4 was about giving them self-awareness. We dove deep into Agent Observability and Evaluation — essentially, the DevOps backbone of the agentic world. In classical systems, debugging meant chasing logs and metrics. But here, we’re not debugging code — we’re debugging thought. The discipline now revolves around understanding how an agent thinks, acts, and learns in real time. Think of this as moving from monitoring to true cognitive observability, where we don’t just ask “Is it running?” but “Is it reasoning correctly?”
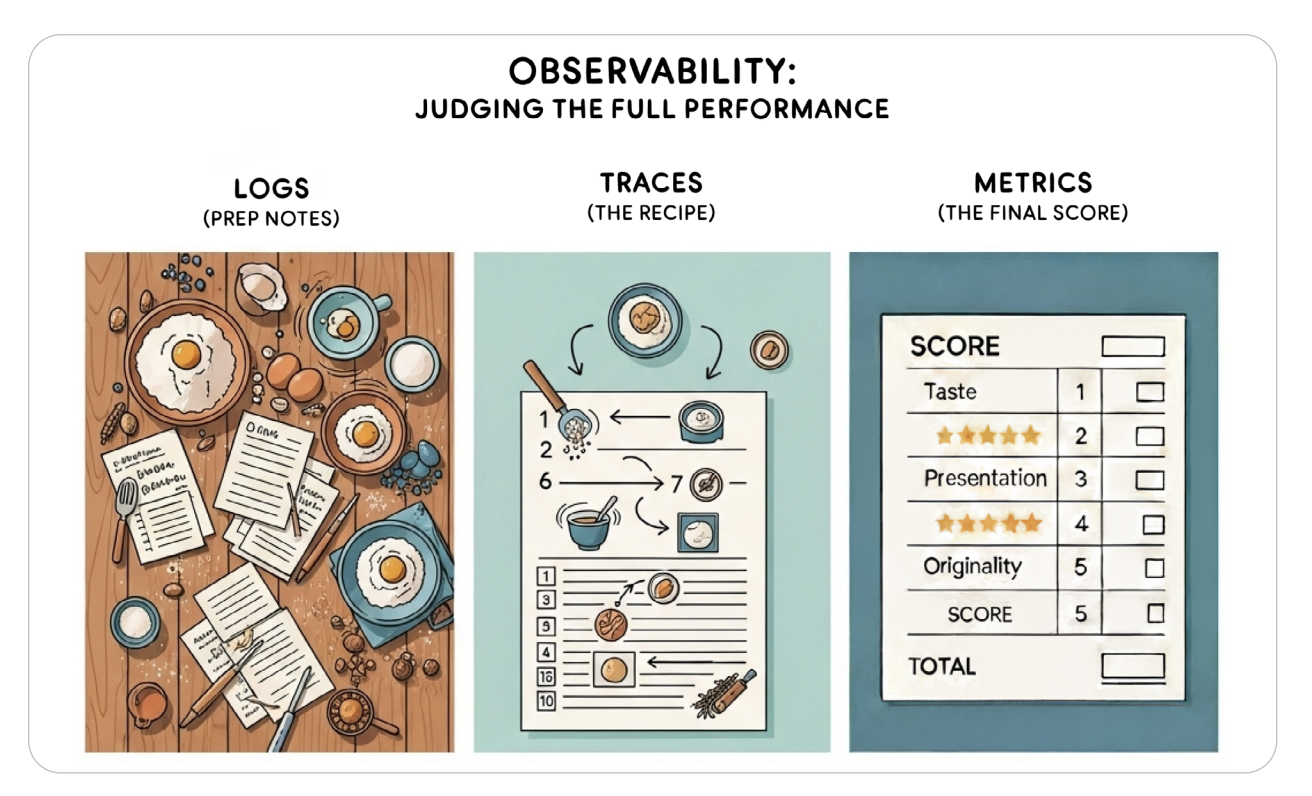 Figure 1 — The Three Pillars of Agent Observability
Figure 1 — The Three Pillars of Agent Observability
🍳 The Kitchen Analogy — From Line Cook to Gourmet Chef
The instructors used the Kitchen Analogy to nail the concept. Traditional software is like a line cook — rigid recipe, predictable output, easy to monitor. But an AI agent is a gourmet chef: given random ingredients and a creative challenge, it must improvise. Observability, then, becomes the food critic’s job — understanding each decision and reasoning step. We’re no longer checking recipes; we’re critiquing cognition.
📊 The Three Pillars — Logs, Traces, and Metrics
Observability for AI agents stands on three core pillars:
- Logs: The agent’s diary — every prompt, tool call, and context update captured in structured JSON.
- Traces: The agent’s footsteps — a narrative chain showing cause and effect between reasoning steps.
- Metrics: The agent’s health report — latency, token cost, and reasoning quality visualized over time.
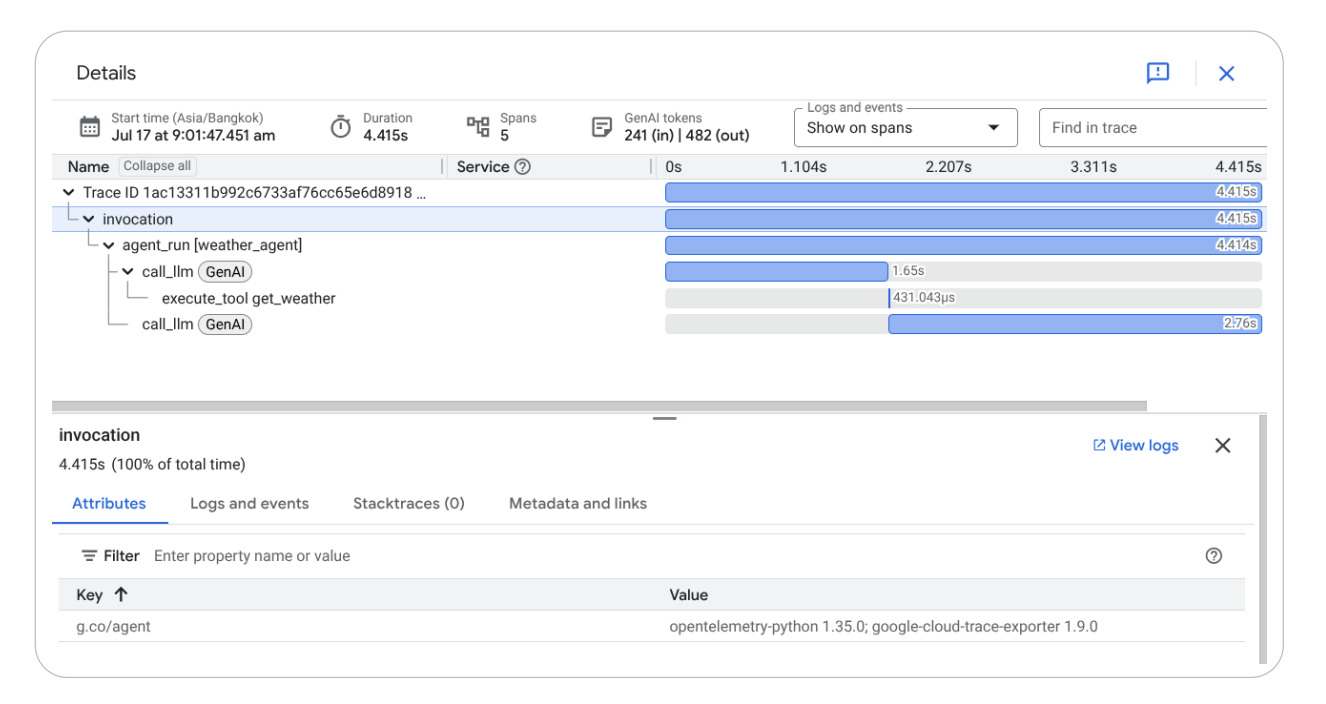 Figure 2 — Distributed Tracing and Observability Visualization
Figure 2 — Distributed Tracing and Observability Visualization
⚙️ Logging Deep Dive — The Agent’s Diary
Using the Agent Development Kit (ADK), we built contextual, structured logs that record every LLM action, tool call, and context mutation. Each log contains IDs, token usage, latency, and reasoning stage. The challenge was balancing verbosity vs. performance — detailed enough to debug, lightweight enough for scale.
 Figure 3 — A structured log entry capturing a single LLM request
Figure 3 — A structured log entry capturing a single LLM request
🔗 Tracing — The Detective’s Red String Board
Tracing links events together into a cohesive story. Every request becomes a trace, each reasoning step a span, annotated with metadata like latency, model ID, and API cost. When something breaks, logs tell you what happened — but traces show why. It’s cognitive forensics at runtime.
Figure 4 — End-to-End Trace for an Agentic Request
📈 Metrics — Quantifying Agent Health
Metrics act as the vital signs of an agent’s mind:
- System Metrics: Latency, token count, error rates, and API cost.
- Quality Metrics: Helpfulness, accuracy, and safety — often evaluated using LLM-as-a-Judge.
💡 Takeaway — Quality Is Architecture, Not QA
Day 4 fundamentally changed how I think about AI reliability. We don’t test agents after deployment — we design them for visibility from the ground up. Logs, traces, and metrics together form the nervous system of intelligent systems, enabling debugging, evaluation, and trust at scale.
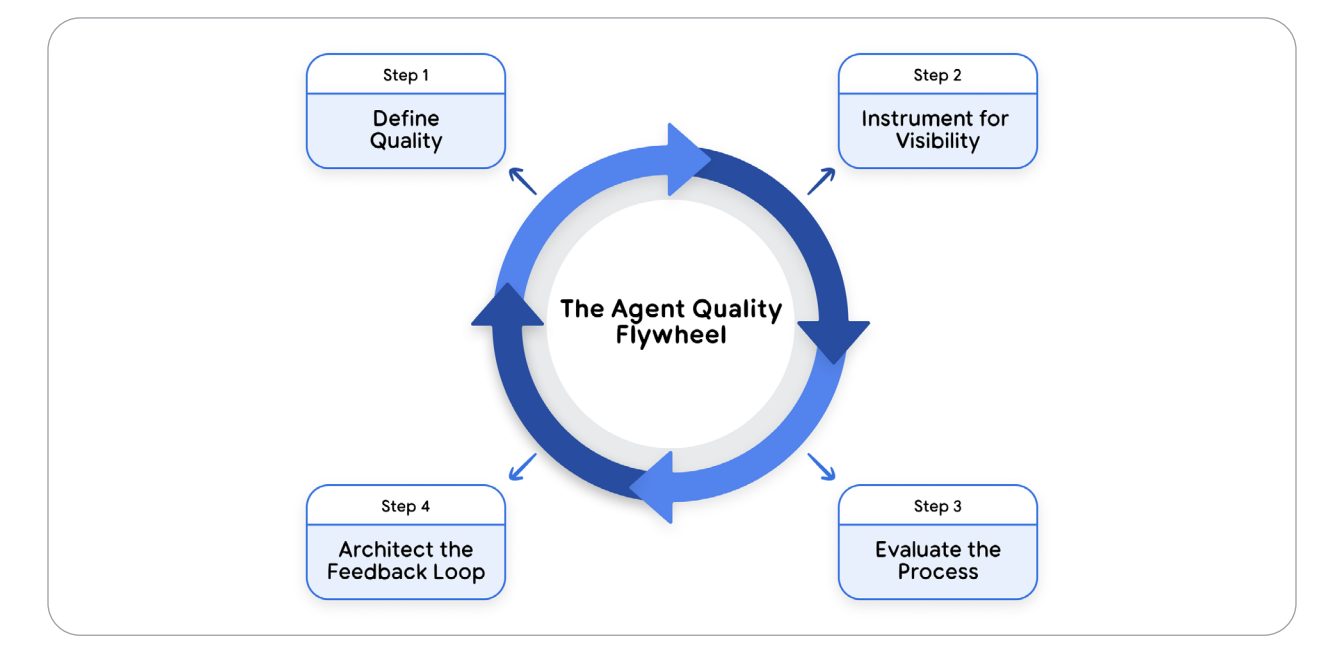 Figure 5 — The Agent Quality Flywheel: Define → Observe → Evaluate → Improve
Figure 5 — The Agent Quality Flywheel: Define → Observe → Evaluate → Improve
🧪 Assignment — Building a Full Observability Pipeline
Day 4a reframed debugging for agentic systems: we’re not only watching code paths, we’re observing reasoning. The stack is the classic triad — Logs (structured, contextual records of prompts, tool calls, and state changes), Traces (end-to-end request timelines with spans for planning, tool execution, and post-processing), and Metrics (latency, token usage, error rates, cost). Together they turn an opaque LLM into a “glass box of cognition.” (https://www.kaggle.com/code/kaggle5daysofai/day-4a-agent-observability)
What we instrumented
- Structured logs with request/response IDs, tool names, token counts, latency, and result status.
- Distributed tracing (e.g., OpenTelemetry) to stitch planning → tool calls → synthesis into one timeline.
- Dashboards to track p50/p95 latency, cost per task, tool failure rates, and retry/circuit-breaker events.
The notebook shows how observability supports AgentOps: you can correlate quality drops with context bloat, mis-routed tools, or model version changes — and then fix with prompts, policies, or tool selection rules. [oai_citation:1‡Kaggle](https://www.kaggle.com/code/kaggle5daysofai/day-4a-agent-observability)
Day 4b moves from visibility to verifiability. You’ll build an evaluation layer that scores responses and tool usage using both offline tests (golden sets, unit scenarios) and online checks (canary/A-B). Core techniques include LLM-as-Judge with rubric prompts (helpfulness, factuality, safety), task-specific metrics (e.g., exact-match, BLEU, JSON-schema validity), and tool-use audits (was the right tool called with the right parameters?).
What we implemented
- Rubric-based judges (accuracy, completeness, safety) with calibrated pass thresholds.
- Regression suites for prompts/tools/config so CI can fail on quality regressions.
- Quality dashboards that join eval scores with observability (latency, tokens, cost) to balance QoS.
The upshot: quality becomes a release gate. Only models/agents that meet target scores and operational SLOs roll forward; everything else is auto-blocked in CI/CD.
You can find the assignment & code in my GitHub repo
Day 5: Prototype to Production
Move from prototype to production by learning how to deploy and scale AI agents for real-world applications. This session covers best practices for operationalizing agents, building multi-agent systems with the Agent2Agent (A2A) Protocol, and deploying on Vertex AI Agent Engine for enterprise-grade scalability.
Day 5 was where everything we learned finally converged into a complete AgentOps lifecycle. It was less about prompts and more about production: scaling, governance, and trust. We explored what Google calls the “last-mile problem”—turning prototypes into reliable, observable, and secure systems. The quote of the day summed it up perfectly: “Building an agent is easy; trusting it is hard.”
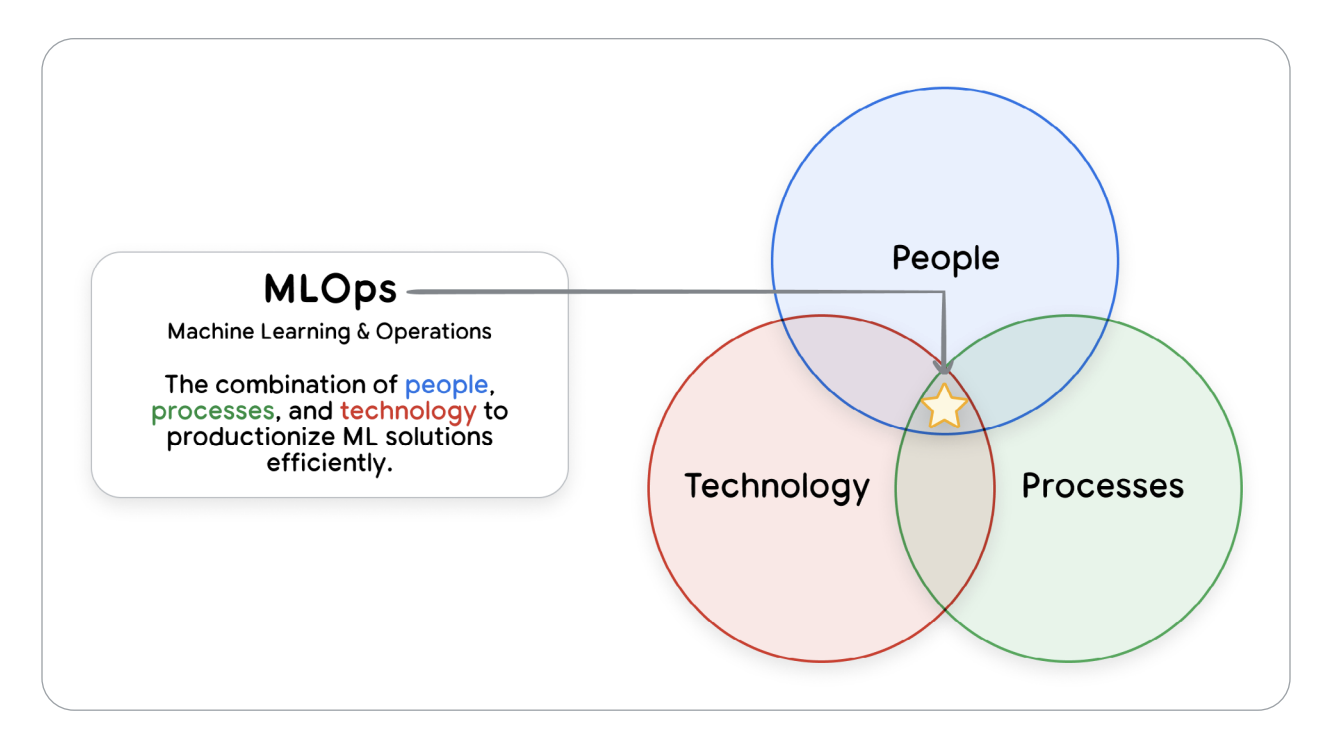 Figure 1 — Prototype → Production Workflow
Figure 1 — Prototype → Production Workflow
⚙️ Closing the Last Mile
We learned that 80% of the work in agent development lies not in intelligence but in infrastructure and operations. Real production agents need evaluation-gated CI/CD, secure state management, and predictable latency/cost controls. Forget fancy prompts—this was systems engineering 101 for cognition at scale.
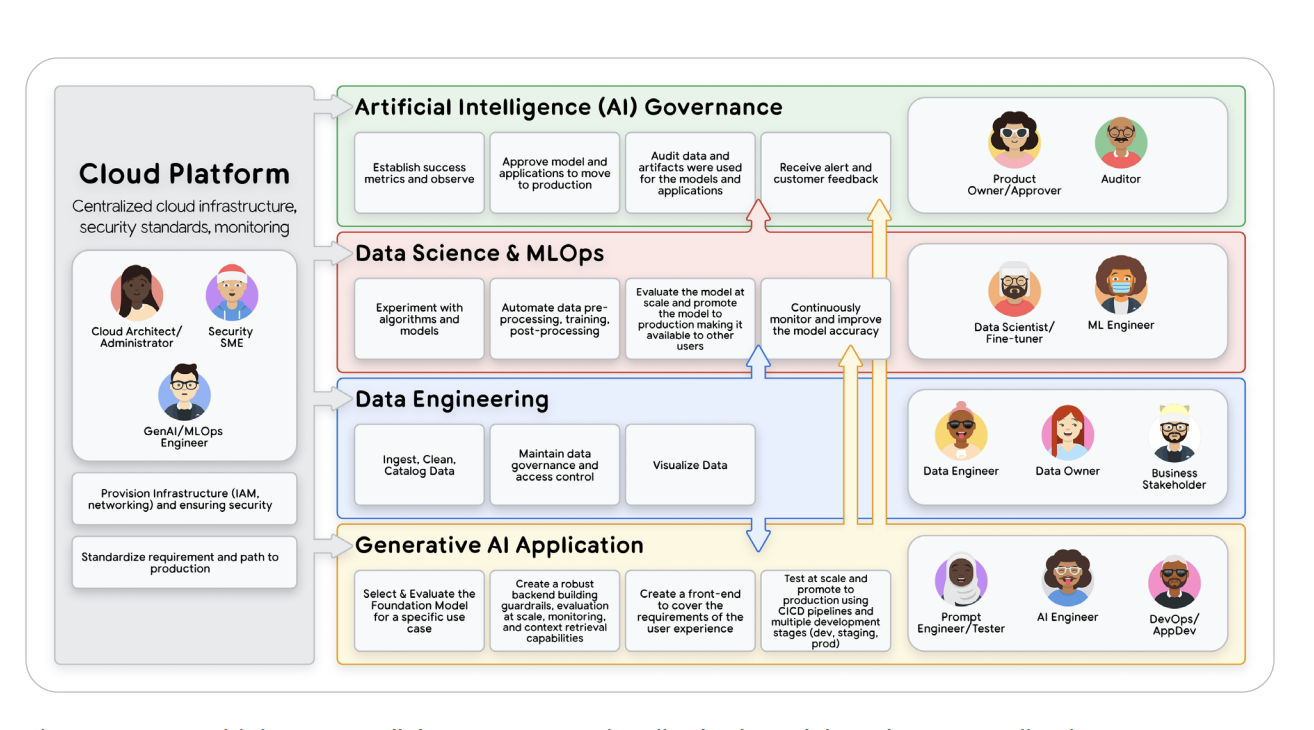 Figure 2 — Evaluation-Gated Deployment Pipeline
Figure 2 — Evaluation-Gated Deployment Pipeline
🧩 The Three Pillars of Production
Production-grade agent systems rest on three foundations:
- Evaluation as a Quality Gate — no agent ships without passing behavioral and guardrail tests, automated via LLM-as-a-Judge frameworks.
- Automated CI/CD — all prompts, tools, and config are version-controlled, validated in staging, and rolled out safely through Terraform and Cloud Build.
- Comprehensive Observability — logs, traces, and metrics expose reasoning paths, latency, and cost through Vertex AI and Cloud Monitoring.
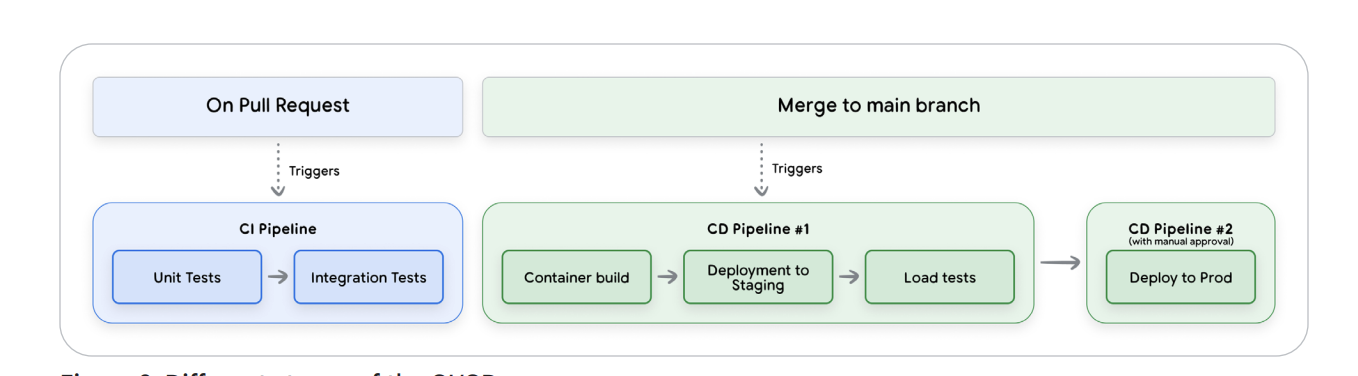 Figure 3 — CI/CD and Observability Loop
Figure 3 — CI/CD and Observability Loop
🔐 Security, Guardrails & HITL
Autonomy without security is chaos. We explored Google’s Secure AI Framework (SAIF) for agents—defining policies, I/O guardrails, and Human-in-the-Loop (HITL) checkpoints. Input filters block malicious prompts; output filters catch PII or toxicity; HITL intervenes when risks spike. Safety is a pipeline, not a policy.
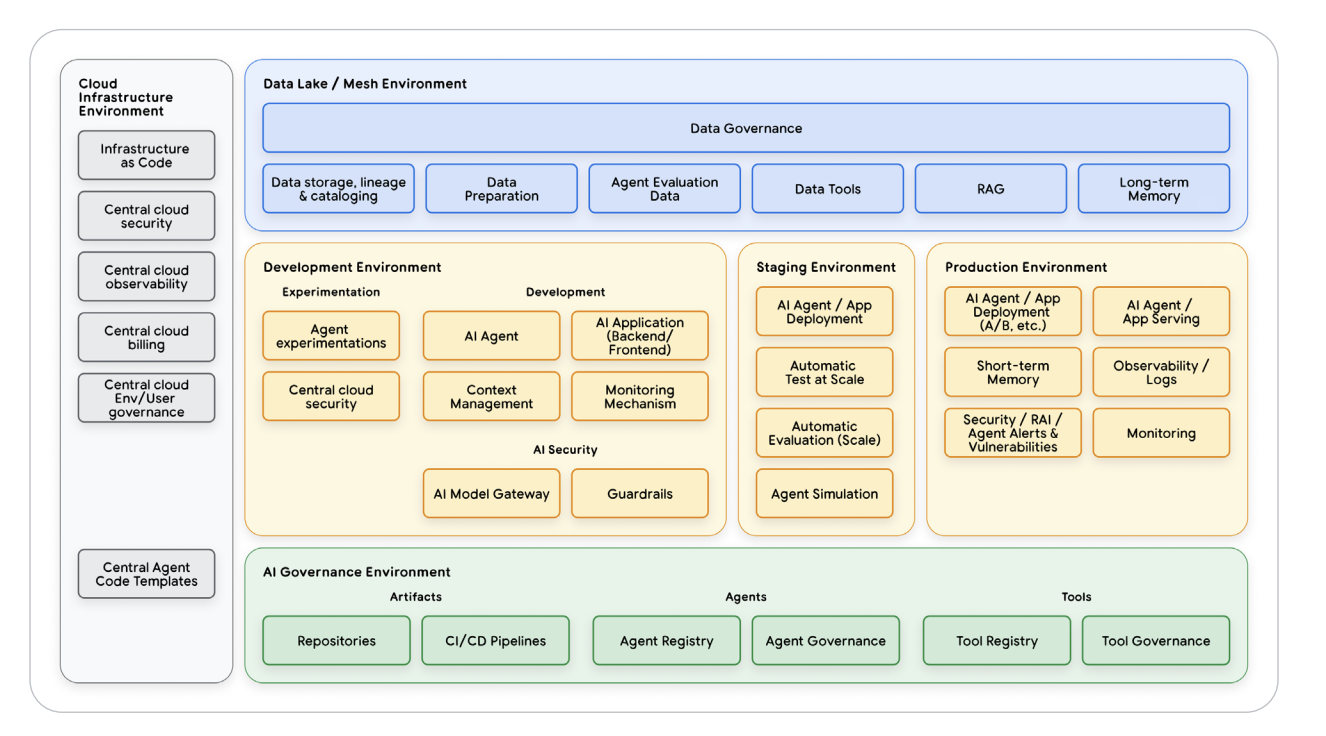 Figure 4 — Secure Agent Architecture with Guardrails & HITL
Figure 4 — Secure Agent Architecture with Guardrails & HITL
🤝 A2A Protocol — Agent Collaboration in Action
Enter the Agent2Agent (A2A) Protocol—the standard that lets agents communicate like microservices. While MCP handles tools, A2A handles agents. Agents exchange JSON-based AgentCards describing their capabilities and delegate complex tasks autonomously. Using ADK’s to_a2a() and RemoteA2aAgent(), we built distributed systems of reasoning peers that plan together like digital colleagues.
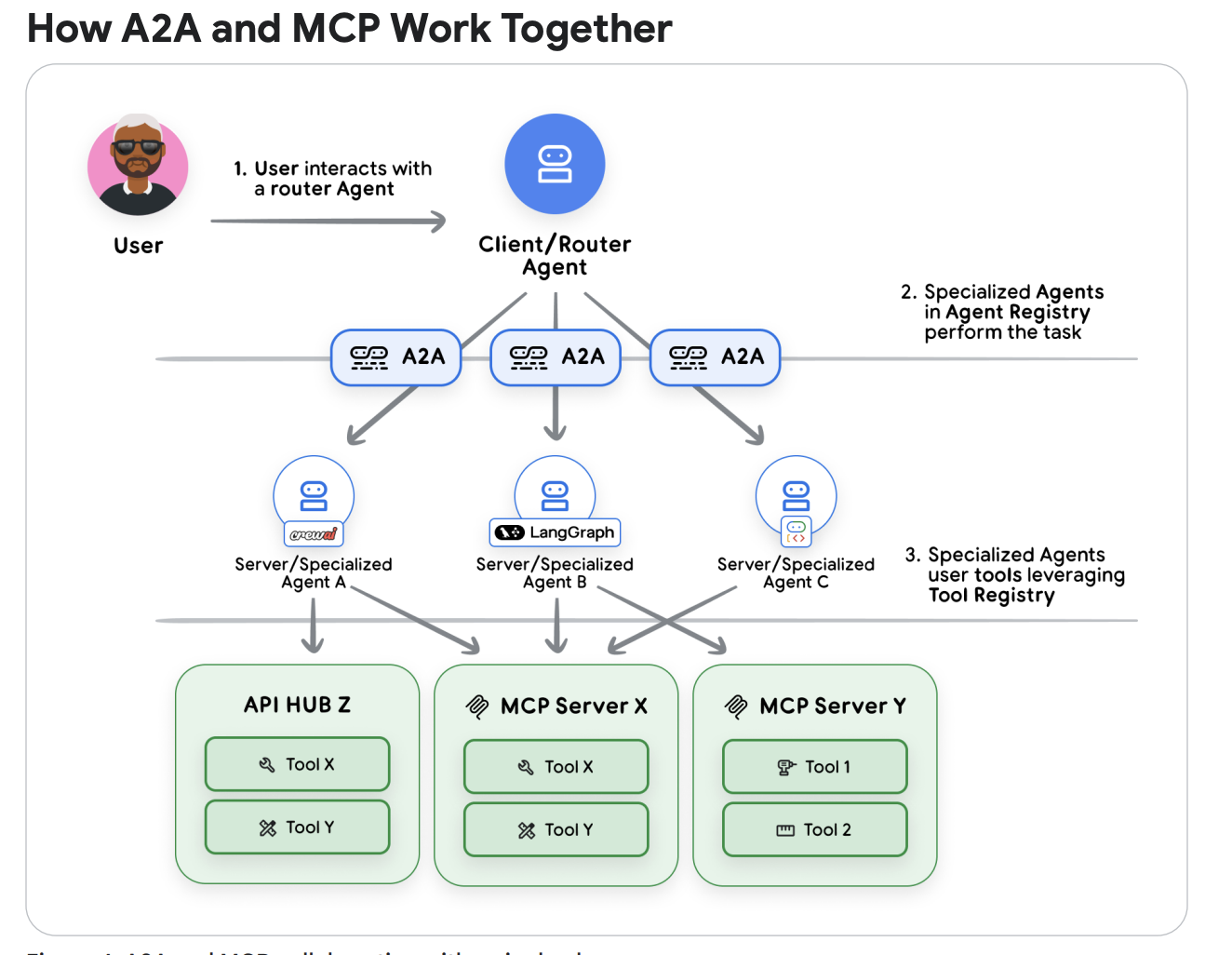 Figure 5 — A2A + MCP Integration
Figure 5 — A2A + MCP Integration
🧬 Observe → Act → Evolve
Once live, agents enter a continuous loop of Observation, Action, and Evolution. Logs feed metrics; metrics trigger tuning; tuning commits new versions via automated CI/CD. This feedback cycle transforms AI from static code to a living system of continuous learning—true AgentOps.
🤝Assignments
Day 5 marked the grand finale of the AI Agents Intensive — where our prototypes graduated to production-grade systems. The focus was twofold: Agent Collaboration (A2A) and Deployment. We first learned how to let multiple agents communicate and coordinate autonomously, then packaged them into containerized, observable services ready for cloud deployment.
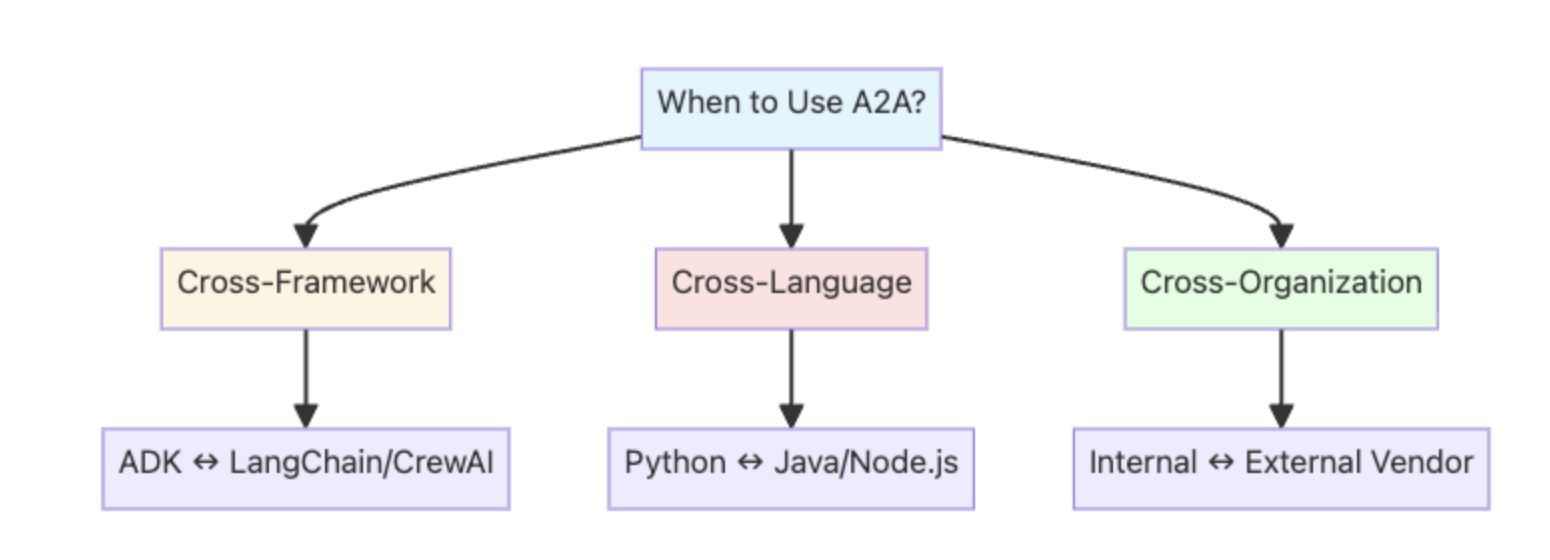 Figure 6 — Multi-Agent Collaboration through A2A Protocol
Figure 6 — Multi-Agent Collaboration through A2A Protocol
🤝 Part 1 — Agent2Agent (A2A) Communication
This assignment introduced Agent2Agent (A2A) communication — a framework where multiple agents act as teammates rather than isolated bots. We designed a Coordinator Agent that decomposed complex problems into subtasks handled by specialized peers like Planner, Researcher, and Writer. Each agent exposed a JSON-based AgentCard describing its capabilities and could call others dynamically using ADK utilities such as to_a2a() and RemoteA2aAgent(). This architecture mirrors microservices — each agent is independent, reusable, and observable.
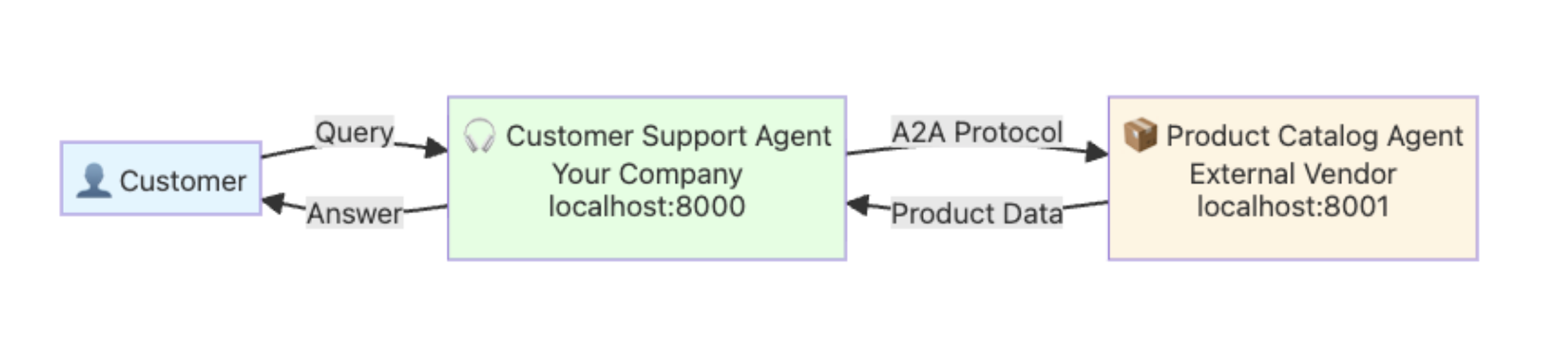 Figure 7 — Coordinator ⇄ Specialist message flow using A2A calls
Figure 7 — Coordinator ⇄ Specialist message flow using A2A calls
What we built
- Defined clear roles & policies for each agent (planner, solver, reviewer).
- Implemented a structured message schema for task handoffs (intent, payload, confidence).
- Created a Coordinator loop to route requests and aggregate responses.
- Enabled agents to invoke external tools and attach results to their A2A messages.
- Added observability hooks to trace handoffs and monitor cost and latency.
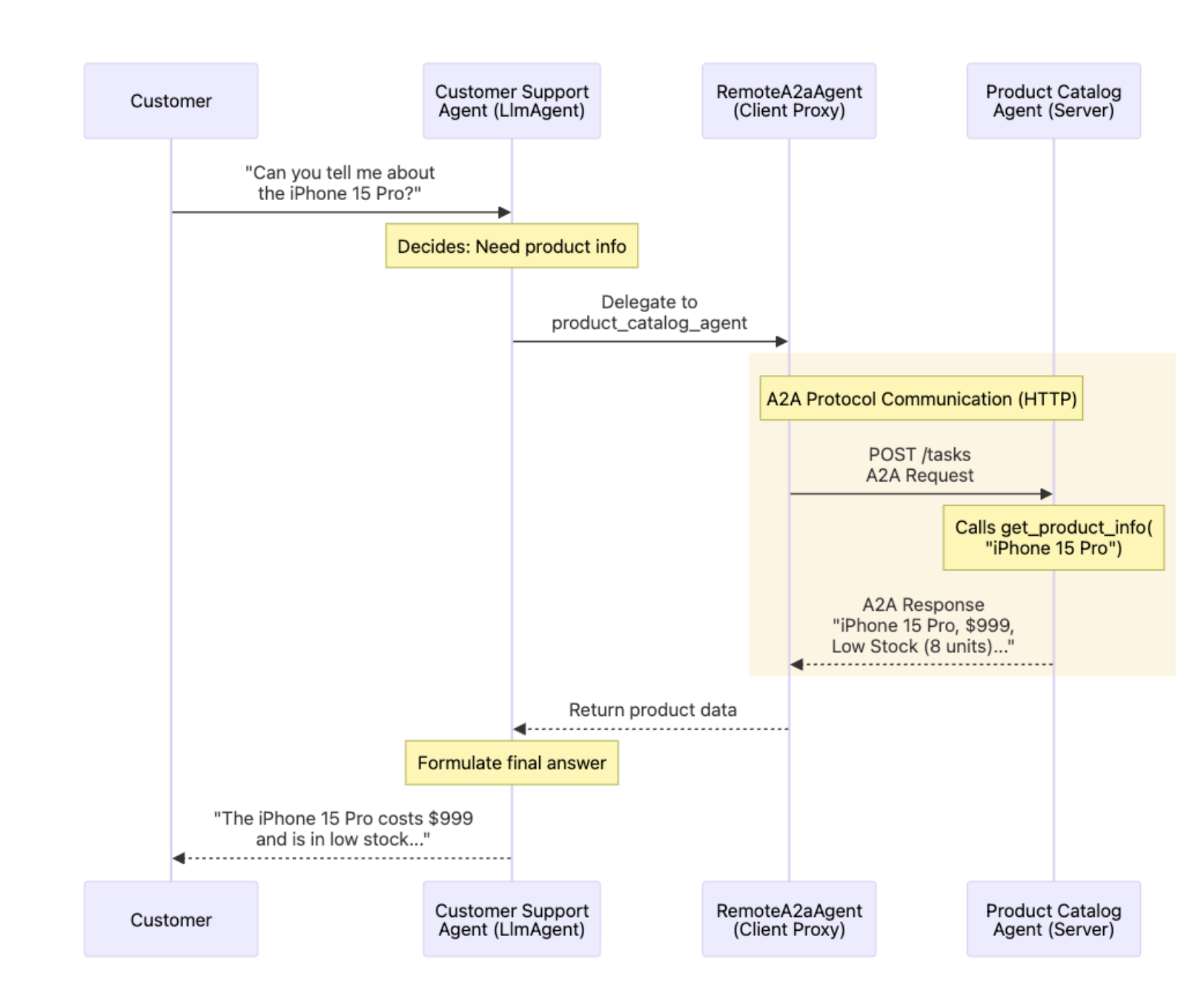 Figure 8 — Tracing A2A handoffs with logs and metrics
Figure 8 — Tracing A2A handoffs with logs and metrics
👉 Try the official A2A assignment on Kaggle: Day-5a: Agent2Agent Communication (Kaggle)
⚙️ Part 2 — Agent Deployment
After collaboration came deployment. We took our A2A ecosystem from local notebooks to the cloud using FastAPI, Docker, and Vertex AI Agent Engine. The goal was to operationalize agents as microservices — versioned, observable, and scalable. Each agent exposed REST endpoints (/invoke, /healthz), ran in a containerized runtime, and was instrumented with logs and traces for AgentOps monitoring.
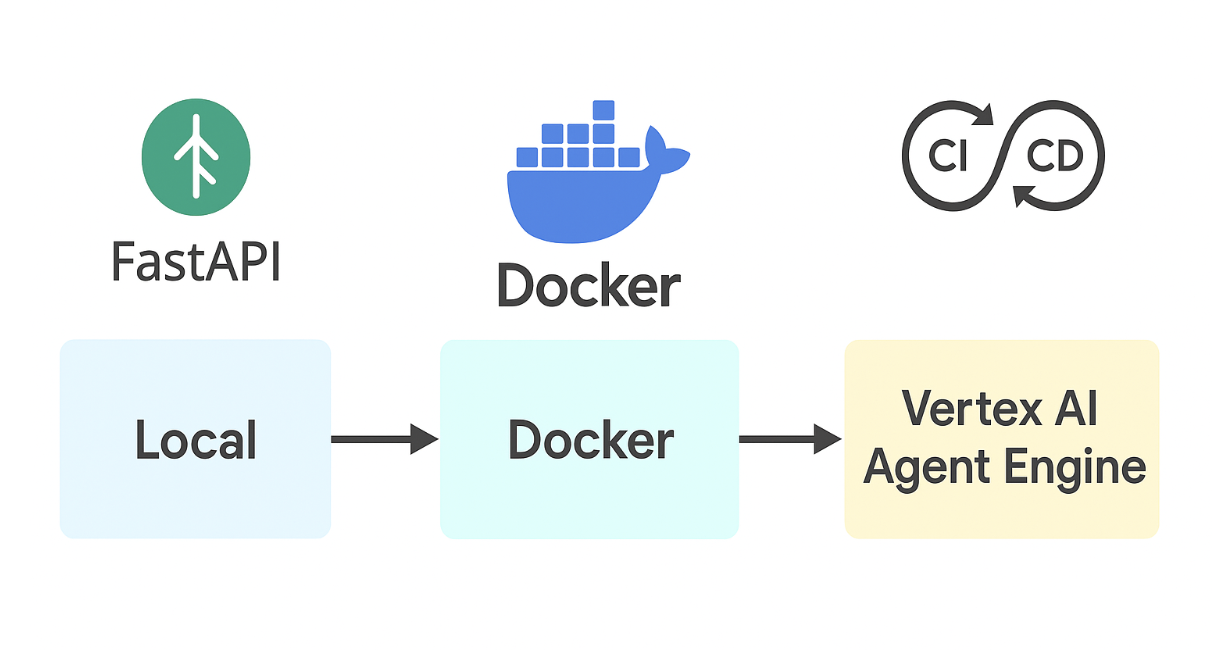 Figure 9 — Local → Docker → Vertex AI Agent Engine Deployment
Figure 9 — Local → Docker → Vertex AI Agent Engine Deployment
Deployment Checklist
- FastAPI endpoints wrapping agent logic (+ health & invoke routes).
- Docker image with locked dependencies and environment variables for secrets.
- Observability — add tracing IDs, structured logs, and custom metrics (cost & latency).
- Continuous Deployment — push image to registry and deploy with autoscaling.
- Safety & QoS — timeouts, retries, and circuit breakers around external tools.
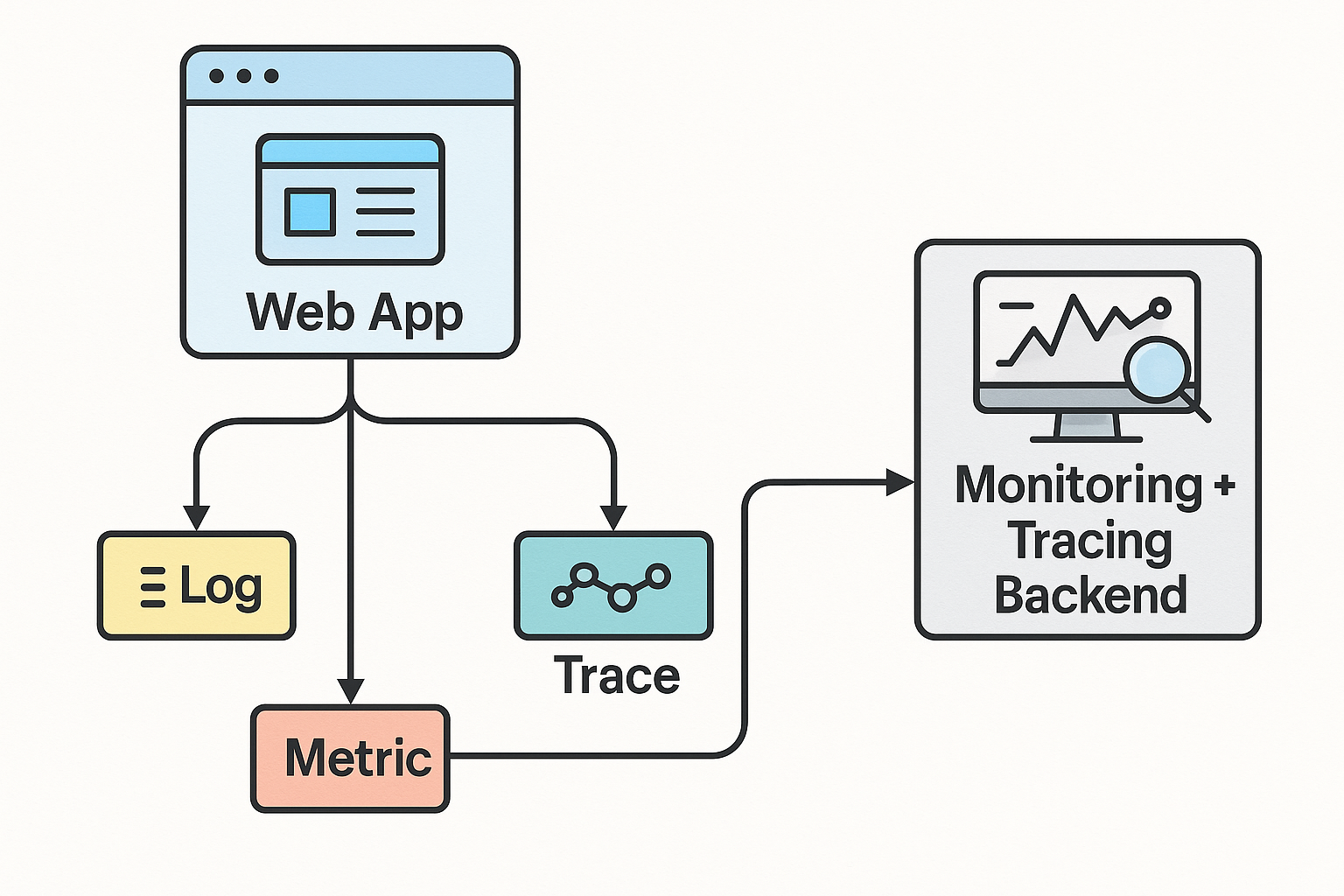 Figure 10 — Observability and Tracing in Production
Figure 10 — Observability and Tracing in Production
👉 Open the official Deployment assignment on Kaggle: Day-5b: Agent Deployment (Kaggle)
💡 Day 5 Takeaway
Day 5 was the ultimate developer flex — building agents that don’t just think or act, but collaborate and ship. We learned how to build autonomous agent teams via A2A and deploy them as scalable services with FastAPI, Docker, and Vertex AI. The future of AI development is clear: don’t just train models — deploy ecosystems that learn, coordinate, and evolve.
You can find the assignment & code in my GitHub repo
🔚 Final Thoughts
The course clarified that real AI agents aren’t just chatbots—they reason, act, observe, and evolve. Translating agent architectures involving tools, orchestration, and memory into working code made advanced research feel truly practical. Understanding how sessions and memory operate shifted my thinking from simple prompt adjustments to complete system design. I also learned that observability and evaluation are not optional—they are essential foundations for building agents that can be trusted, scaled, and maintained over time. The journey from prototype to cloud deployment demonstrated how agent engineering has matured into a production-ready discipline. I now see myself working at the intersection of research and production, where tooling, governance, and architecture matter as much as the underlying models. If you’re planning to build agents, this program is the perfect launchpad—technical, hands-on, and directly relevant to real-world challenges.